
Agentic Systems: From RL to LLMs
In this article, we explore how core reinforcement learning concepts—Agent, Environment, and Reward—are being used to iteratively finetune complex multi-turn AI agents built with frameworks like LangGraph.
The Agent as a Policy (LangGraph)
In a traditional RL setup, the Policy is a function that maps states to actions. In our Agentic System, the Policy is the Large Language Model (LLM) fine-tuned to navigate a complex decision graph. Using LangGraph, we define the agent’s logic—its cyclical ReAct pattern of Thought, Tool Call, Observation—making the LLMs choices the central action being reinforced.
The Environment (The Rollout Loop)
The Environment is where the agent performs its task. For an LLM agent, this is often an iterative loop, or a Rollout. Using a framework like ART, the rollout is defined as the process where the agent:
- Receives a Scenario (the prompt and context).
- Executes its LangGraph workflow (making tool calls, generating thoughts).
- Terminates upon reaching a final answer or max turns, generating a full Trajectory (the sequence of messages and tool logs).
Defining Success: The Reward Function
The key to RL finetuning is the Reward Function, which measures the value of the agent’s final answer. In agentic systems, this often involves multiple verifiable metrics, not just a single score. Our Fitness Agent example used a composite reward:
- Verifiable Rewards: Checking if the generated meal plan adheres to strict technical constraints (e.g., daily macros are
\pm 5\%of the target, using correct schema, no banned ingredients are present).
The Training Loop
The training process takes the gathered trajectories and their calculated rewards to iteratively update the LLM’s weights. Trajectories with high rewards are reinforced, teaching the agent to produce better outputs and more effective tool-use sequences in future rollouts. This allows the agent to learn complex, multi-step reasoning that simple Supervised Fine-Tuning (SFT) often misses.
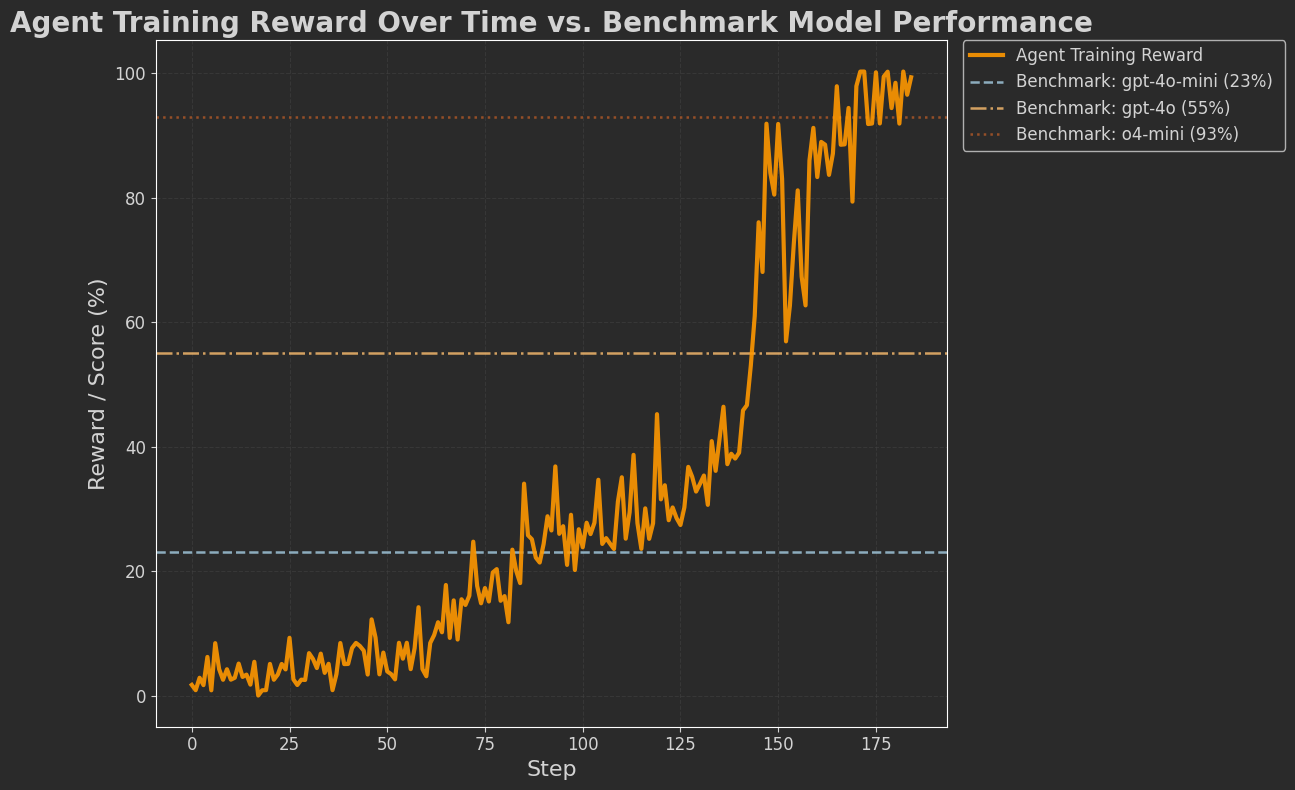
Results
From the plot below we can see that after some step of the training the agent learns to outperfrom some of the openai modesl (gpt-4o-mini, gpt-4o, o4-mini) and learn to perfrom the task correctly.
A Beauty And the Beast
We saw that the agent learns to maximize the reward score we defined. We saw that in the beautiful reward score that is increasing and finally reach the maximum score. That means agent learn to create 7-day meal plans that align with the macros and food preferences of the user and also follow a specific format. But is it actually that we have build the perfect agent for nutrition now? Absolutely not, and this article aims also to highlight the importance of the reward function definition of training the agents. And in this experiment the above reward function (and agent architecture) is simply not accurate enough. For the main big reason, that it does not adress if the nutrition facts of the meal that is inserted/generated by the agent corresponds to the correct and actual nutrition facts of the meal. Sothe agent we trained j may propose some nutrition facts for a meal that are inaccurate just to be able to pass the macro check reward. And 'cheat' its way to getting a daily meal plan that is aligned with the user target macros.
How can we tame the Beast?
So, in order to tame the Beast and have only (hopefully) the Beauty, we need to address the above problem. We need to add to the reward function another verifiable reward that will check that the nutritional info of the meal that is inserted by the agent is the true one. And we nned another tool fo the agent that will retrieve meals from a database along with the correct nutritional info. If the meal tht agetn inserted in the final answer plan, is not the same as teh meal and nutrition nfo retrieved from the RAG search then agent will not be rewarded at all.
Experiment Details
The following experiment ran for 2 days in the Google Colab. Unfortunately, it require two running sessions (even Colab+ limits only for 24h background execution). Fortunately though, ART enables to continue training from last step checkpoint, so basically the it was just a simple 2nd run. Code is available here https://github.com/SOCAIT/SOAR-fitness-agent-rl.git