
Building Semideus: A Production-Grade Multi-Agent AI System for Health & Fitness
In this article I present SemiDeus, an agentic sytem that tries to make fitness and learning easier and verifiable.
System Architecture
The architecture follows a layered design: a Client Layer (mobile, web, and A2A agents) communicates over HTTPS + JWT with the API Gateway running on FastAPI. Behind the gateway sits the Agent Orchestration Layer built on LangGraph, which routes requests through a Supervisor Node to specialized sub-agents. The Data & Persistence Layer combines PostgreSQL, Supabase, Pinecone, and mem0 for vector memory. The Observability Layer ties everything together with Langfuse, Prometheus, and Grafana.
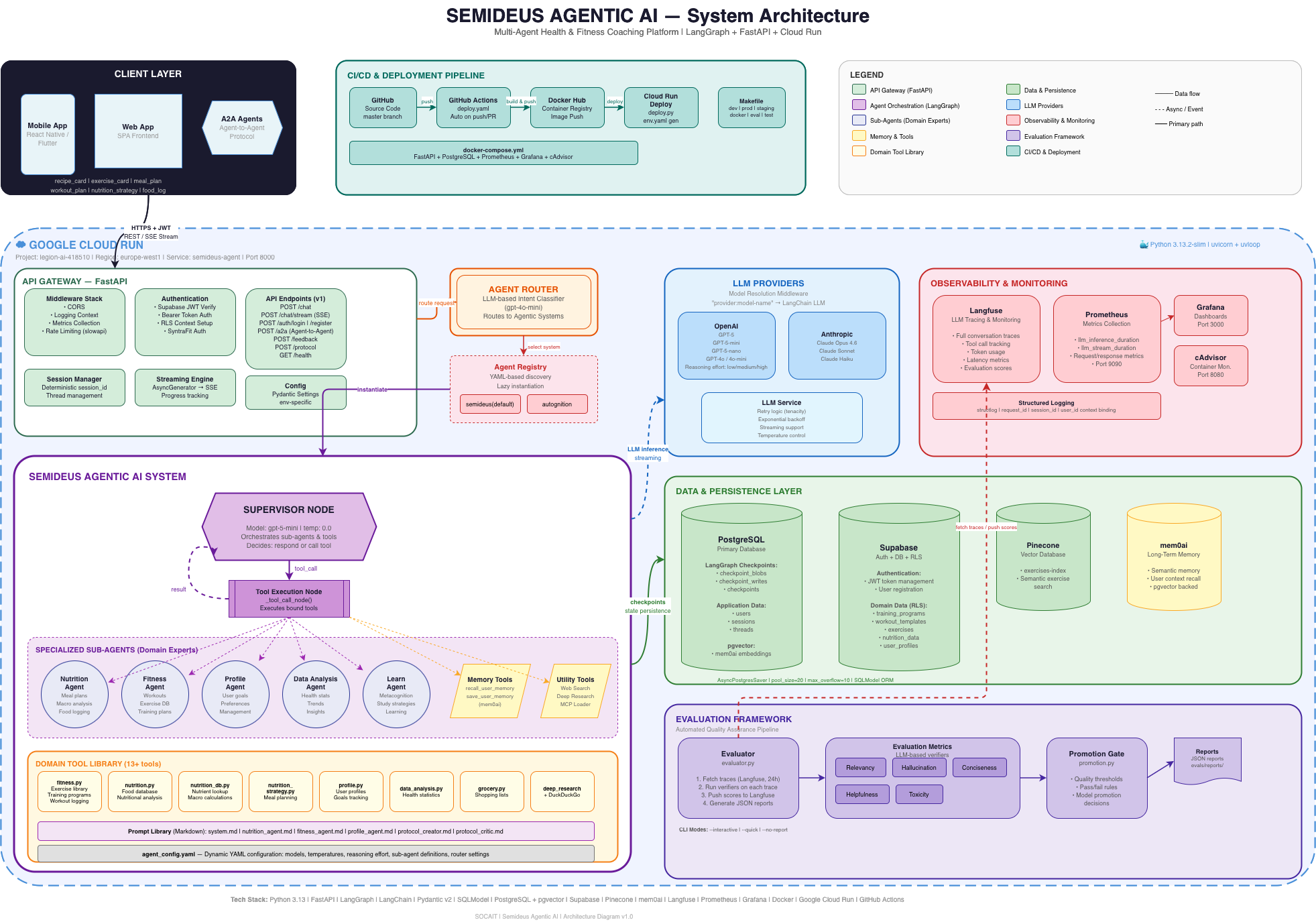
The entire system is containerized with Docker, deployed via a CI/CD pipeline (GitHub Actions → Docker Hub → Google Cloud Run), and monitored through Prometheus metrics with Grafana dashboards. The Python runtime is 3.13, managed with uv for fast dependency resolution.
The Supervisor Pattern: LangGraph at the Core
At the heart of Semideus is a Supervisor Node — a LangGraph StateGraph that acts as the central reasoning engine. It receives every user message, decides whether to respond directly or delegate to a specialized sub-agent, and orchestrates multi-step tool calls with a recursion limit of 40 iterations.
The supervisor uses gpt-5-mini as its default model, with dynamic model selection based on model_tier (standard vs. thinking). When a user asks something that requires domain expertise — say, building a nutrition strategy or analyzing workout trends — the supervisor invokes the appropriate sub-agent as a tool call, passing along full context including user profile, memory, and session state.
Conversation state is checkpointed with AsyncPostgresSaver, which means sessions are persistent across requests. The system can pick up exactly where it left off, even after server restarts or horizontal scaling events.
Five Specialized Sub-Agents
Rather than stuffing everything into a single monolithic prompt, I designed five domain-expert sub-agents, each with its own system prompt, toolset, and model configuration:
- Nutrition Agent — Handles meal planning, macro calculations, food logging, nutrition strategies, and grocery lists. Equipped with 14 tools including USDA food database search, Pinecone-powered semantic food search, macro target calculations (Mifflin-St Jeor / Katch-McArdle BMR), and meal slot validation.
- Fitness Agent — Manages workout programming, exercise search (Pinecone semantic + Supabase), exercise logging with RPE tracking, training program creation with multi-week periodization, and workout session management. 6 specialized tools.
- Profile Agent — Manages user demographics, goals, dietary restrictions, health metric logging (weight, sleep, HRV, resting heart rate, steps, stress, readiness), and user settings. 4 tools.
- Data Analysis Agent — The analytics powerhouse: health metric trends, personal records, exercise history, workout session analysis, and body composition tracking with moving averages. 5 tools.
- Learn Agent — A spaced-repetition learning system with learning paths, modules, knowledge cards (flashcards), challenges, teach-back evaluation, and SM-2 review scheduling. 11 tools.
Each sub-agent returns structured JSON responses with optional UI widgets — structured data payloads that the frontend can render as cards, charts, lists, or interactive elements. This gives the system a hybrid interface: conversational AI with rich, actionable UI components.
The Domain Tool Library: 30+ Specialized Tools
One of the most engineering-intensive parts of this project was building the tool library. Each tool is a carefully designed function that interacts directly with Supabase — no REST API wrappers, just direct database operations for lower latency and higher reliability.
Here's a sample of what the tools can do:
- calculate_macro_targets — Evidence-based BMR/TDEE calculations with goal-specific macros, delta clamping (±300 kcal per cycle), and calorie ramp-up for metabolic safety
- validate_and_create_nutrition_strategy — Full validation pipeline: macro–calorie consistency (P×4 + C×4 + F×9 ≈ total_kcal), meal slot sum checks (±5% tolerance), and 2–8 meal slot support
- exercise_search — Semantic exercise search via Pinecone with OpenAI embeddings, with Supabase text fallback
- submit_workout_plan — Creates multi-week periodized training programs with templates, exercises, sets, reps, rest periods, and tempo prescriptions
- calculate_plan_variety — 7-day meal plan analysis with variety scoring, repetition warnings, and consecutive-day similarity checks
- submit_grocery_list — Generates categorized grocery lists (protein, carbs, produce, dairy, pantry, supplements) with cost estimates
Beyond the sub-agent tools, the supervisor also has access to memory tools (recall and save via mem0), DuckDuckGo web search, and an MCP loader that dynamically loads tools from external Model Context Protocol servers.
Automated Nutrition Adaptation Pipeline
This is one of the features I'm most proud of. The Nutrition Adaptation Workflow is a standalone LangGraph pipeline that automatically adjusts a user's nutrition strategy based on real data — no manual intervention required.
The pipeline runs through five nodes:
- Data Collector — Aggregates 30 days of health metrics, 14 days of nutrition logs, active strategies, training programs, workout sessions, and exercise logs from Supabase. Computes weight moving averages (7d, 30d), weekly rate of change, anomaly detection, macro adherence, training volume/frequency, and sleep/recovery averages.
- Calculator — Pure math node: runs BMR (Mifflin-St Jeor, Katch-McArdle, Cunningham), TDEE with NEAT adjustments, rate-based deficit/surplus tuning, and delta clamping to ensure changes are gradual and metabolically safe.
- Adapter — An LLM agent that takes the calculated targets and trend analysis, then proposes structured adaptation recommendations with rationale.
- Validator — A separate LLM agent that evaluates the proposed adaptations for safety, dietary restriction compliance, and overall quality. If it rejects, the adapter revises (up to 3 rounds).
- Save — Persists the approved adaptation back to Supabase.
This pipeline can be triggered per-user or as a batch job via a cron endpoint (POST /nutrition/adapt-all), enabling fully automated periodic nutrition adjustments for the entire user base.
Creator-Critic Protocol Generation
I also implemented a Creator-Critic workflow for generating personalized health protocols. A "creator" LLM drafts a comprehensive protocol, and a "critic" LLM reviews it for completeness, accuracy, and personalization. The loop continues until the critic approves or a maximum revision count is reached. This pattern ensures higher-quality outputs than single-pass generation.
Long-Term Semantic Memory
Short-term context lives in the LangGraph checkpointer. But for long-term memory — user preferences, recurring patterns, past decisions — I integrated mem0ai with pgvector as the vector store backend.
The supervisor can recall_user_memory (semantic search across all stored memories for a user) and save_user_memory (persist new insights). Embeddings are generated with OpenAI's text-embedding-3-small, and the LLM layer uses gpt-5-nano for memory extraction. Every memory is scoped per user_id, ensuring complete data isolation.
After each conversation turn, the system also runs an async background task to update memories with any new information from the exchange — the user never waits for this.
Real-Time SSE Streaming
For a responsive user experience, the system implements Server-Sent Events (SSE) streaming via POST /chatbot/chat/stream. As the agent reasons, calls tools, and generates responses, events are streamed in real-time to the client:
status— "Thinking…", "Preparing response…"tool_call— Tool name and arguments as the agent actstool_result— Tool completion signalsreasoning— Reasoning blocks (when using thinking models)token— Text chunks as they're generatedwidget— Structured UI component datadone— Stream complete with all accumulated widgets
The streaming implementation includes keep-alive pings, a configurable timeout (default 300 seconds), and a progress queue for sub-agent status updates, so the user always knows what the system is doing.
A2A Protocol: Agent-to-Agent Communication
A major technical milestone was implementing the A2A (Agent-to-Agent) protocol. This enables external AI agents to discover and communicate with the Semideus system through standardized endpoints.
The implementation includes a discovery endpoint (GET /.well-known/agent-card.json) that describes the agent's capabilities, and message endpoints for both synchronous and streaming communication. The protocol supports standard A2A message formats with task states (COMPLETED, WORKING, FAILED), plus a LangSmith-compatible fallback mode. This means Semideus can participate in multi-agent ecosystems alongside other A2A-compatible systems.
Observability: Langfuse, Prometheus & Grafana
Production AI systems need deep observability. Semideus implements three layers:
- Langfuse — Full conversation traces for every LLM call. Every agent invocation, tool call, and response is traced with session grouping and user attribution. The system also supports user feedback submission via
POST /chatbot/feedback, which feeds back into Langfuse for analysis. - Prometheus — Custom metrics including
http_requests_total,http_request_duration_seconds,llm_inference_duration_seconds,llm_stream_duration_seconds, anddb_connections. These are exported via a/metricsendpoint and scraped by Prometheus, with remote write to Grafana Cloud. - Grafana — Pre-configured dashboards for API performance, LLM latency, token usage, and system resource utilization. Plus cAdvisor for container-level metrics.
The logging infrastructure uses structlog with context binding (request_id, session_id, user_id) and environment-specific formatting — human-readable in development, JSON in production.
Automated Evaluation Framework
How do you know your AI agent is actually good? I built a complete evaluation framework with LLM-based and deterministic verifiers.
The framework fetches recent Langfuse traces, runs them through evaluation "slices" (named groups of verifiers), and pushes scores back to Langfuse. The evaluation metrics include:
- LLM-based metrics — Helpfulness, Relevancy, Toxicity, Hallucination, Conciseness
- Deterministic verifiers — ContainsVerifier, MaxLengthVerifier, NotContainsVerifier
- Domain-specific verifiers — FactualNutritionVerifier, NutritionHasRequiredFieldsVerifier, NutritionMacroConsistencyVerifier, NutritionSlotSumVerifier
The system also implements Promotion Gates — quality thresholds that must be met before deploying changes. The overall success rate must be ≥80%, and protected slices (like nutrition plans) require ≥95% pass rate. This ensures that updates don't degrade the agent's output quality.
Authentication & Security
The API is secured with Supabase JWT authentication. Bearer tokens from the client are verified server-side, and user identity is extracted from the token payload. Session IDs are deterministically generated from token hashes, enabling persistent sessions without additional database lookups.
Additional security layers include rate limiting via slowapi (e.g., 30 req/min for chat, 20 req/min for streaming), CORS configuration, and middleware for logging context injection. All sensitive configuration lives in environment-specific .env files, never in code.
Deployment & CI/CD
The full deployment stack is containerized:
- Dockerfile — Python 3.13.2-slim image with uv for dependency management, running as a non-root user
- docker-compose.yml — Full local stack: app, pgvector database, Prometheus, Grafana, and cAdvisor
- GitHub Actions — CI/CD pipeline triggered on push/PR to master: builds production image and pushes to Docker Hub
- Google Cloud Run — Production deployment target with auto-scaling, deployed via
make cloud-run-deploy - Makefile — Developer-friendly commands:
make dev,make staging,make prod,make eval,make docker-run
The Data Model
The Supabase-backed data model covers the full health and fitness domain:
- Users & Profiles — users, user_profiles (demographics, goals, experience, dietary restrictions), user_settings
- Nutrition — nutrition_strategies, meal_plan_templates, nutrition_logs, grocery_lists
- Fitness — exercises, training_programs, workout_templates, workout_template_exercises, workout_sessions, exercise_logs, exercise_prs
- Health — health_metrics (weight, sleep, HRV, resting HR, steps, stress, readiness)
- Learning — learning_paths, learning_modules, knowledge_cards with SM-2 spaced repetition
- Memory — mem0 embeddings stored in pgvector for semantic retrieval
Configuration as Code
The entire agent system is configured through a single agent_config.yaml file — models, temperatures, reasoning effort, sub-agent definitions, prompt file paths, memory settings, graph parameters, and router configuration. This makes it trivial to experiment with different model combinations or add new sub-agents without touching application code.
The prompt library uses Markdown files loaded at runtime with dynamic variable injection ({agent_name}, {user_id}, {user_context}, {current_date_and_time}), keeping prompts version-controlled and easy to iterate on.
Tech Stack Summary
Here's the full technology stack that powers Semideus:
- Runtime — Python 3.13, uv package manager
- Framework — FastAPI (async, high-performance)
- Agent Orchestration — LangGraph (StateGraph, AsyncPostgresSaver)
- LLM Abstraction — LangChain (tool binding, callbacks)
- LLM Providers — OpenAI (gpt-5-mini, gpt-5, gpt-4o), Anthropic (Claude Opus)
- Vector Search — Pinecone (exercises, food), pgvector (memory)
- Database — PostgreSQL via Supabase
- Long-Term Memory — mem0ai with pgvector backend
- Observability — Langfuse (LLM traces), Prometheus (metrics), Grafana (dashboards)
- Auth — Supabase JWT
- Logging — structlog (structured, context-bound)
- Rate Limiting — slowapi
- Retries — tenacity (exponential backoff)
- Deployment — Docker, GitHub Actions, Google Cloud Run
- Data Validation — Pydantic v2
Key Engineering Decisions & Lessons
- Sub-agents over monolithic prompts. Splitting domain expertise into separate agents with focused tools dramatically improved response quality and made the system maintainable. Each sub-agent can be tested, evaluated, and iterated on independently.
- Direct Supabase over REST wrappers. By replacing earlier API wrapper patterns with direct Supabase client calls in every tool, I eliminated an entire layer of latency and points of failure.
- Creator-Critic loops for quality. Both the nutrition adaptation and protocol generation pipelines use a multi-turn review pattern. The initial output is rarely the final output — the critic catches edge cases the creator misses.
- Evaluation-driven development. Building the eval framework early forced me to define what "good" looks like quantitatively. Promotion gates prevent regressions from reaching production.
- YAML-driven configuration. Making models, prompts, and agent definitions configurable via YAML means experimenting with new models or adding sub-agents takes minutes, not hours.
- Async everything. Every database call, LLM invocation, and external API request is async. Combined with FastAPI's event loop, this keeps the system responsive even under concurrent load.
What's Next
Semideus is actively evolving. On the roadmap:
- Expanding the A2A protocol for multi-agent ecosystem participation. The core idea is how semideus cam be used by other agents.
- Adding more evaluation slices and tightening promotion gates
- Implementing RAG pipelines with Qdrant for knowledge base retrieval
- Building the Autognition sub-system for metacognitive learning
- Deeper Pinecone integration for personalized exercise and meal recommendations
- Mobile-first client application with real-time widget rendering
Building Semideus has been one of the most challenging and rewarding engineering projects I've undertaken. It sits at the intersection of backend systems design, machine learning operations, domain modeling, and product thinking. If you're working on agentic AI systems or have questions about the architecture, I'd love to connect.
The full architecture diagram and system documentation are available on the project repository. Built with Python, FastAPI, LangGraph, LangChain, Supabase, Langfuse, Prometheus, and deployed on Google Cloud Run.